
Operational Limits of Rule Based SIEM: Why Correlation Logic Alone Fails at Scale?
If you’ve operated a SIEM in a real production environment, you already know the uncomfortable truth:
SUMMARIZE WITH AI



- Jun 08, 2026
.svg)




If you’ve operated a SIEM in a real production environment, you already know the uncomfortable truth: it doesn’t “break” overnight. It slowly collapses under the scale. At first, everything looks manageable, logs are flowing, dashboards are lighting up, correlation rules are firing. But as soon as organization moves deeper into cloud, adopts SaaS at scale, and starts running workloads in Kubernetes, SIEM operations become less about security and more about survival.
This isn’t because your SOC team lacks expertise. And it isn’t because the SIEM vendor’s rule pack is “bad.” The core issue is architectural. Traditional SIEMs were designed for a world where telemetry was predictable, mostly on-prem, and relatively low-volume. Today, telemetry is high cardinality, distributed, and extremely dynamic.
In practical terms, your SIEM is being asked to process data that is not just “more logs,” but a fundamentally different class of data. Cloud telemetry isn’t a neat sequence of authentication failures and firewall blocks. It is API calls, role assumptions, token issuance, session activity, ephemeral workloads, and transient IP addresses that have no stable identity. The SIEM’s job is no longer correlating events; it is trying to reconstruct system reality from fragmented signals. And this is where things start failing.
Traditional correlation engines assume a bounded input space: a stable set of hosts, predictable user behavior, consistent log formats, and long-lived identities. But in cloud-native environments, almost everything violates those assumptions. Instances scale up and down automatically. Containers are destroyed and recreated. Identity is federated. Access happens through service principals. And the same user might authenticate from multiple devices through multiple identity providers in the same day.
This creates what we can describe as high-entropy telemetry. The SIEM correlation engine does not just face more data; it faces data with far more variance, far more dimensionality, and far less stable structure. As a result, correlation rules that were designed for deterministic environments become unstable. They either fire too often (noise explosion) or fail to fire when they should (detection blind spots).
This is the scaling crisis. Not a performance issue. Not a storage issue. A detection logic issue.
How Rule-Based SIEM Actually Works (and Why It Was Initially Effective)
To understand why rule-based SIEM struggles today, it’s worth revisiting why it worked so well in the first place. SIEM platforms were originally built around a relatively straightforward security model: collect logs, normalize them, apply correlation logic, and generate alerts. The assumption was that meaningful attacks leave behind recognizable sequences of events, and those sequences can be represented as deterministic rules.
This approach was extremely effective in the era of perimeter security. Most enterprises had stable network boundaries, a controlled set of endpoints, centralized authentication systems, and a limited number of security telemetry sources. If a malicious actor attempted lateral movement, brute-force login, or privilege escalation, their activity was likely visible through a narrow set of log types.
But SIEMs didn’t “detect threats” in an intelligent way. They detected known patterns. They were essentially rule execution engines operating on security telemetry. Once your team had good correlation rules, detection became reliable and repeatable. This is why SIEMs became the backbone of SOC operations for over a decade.
The problem is that the same architecture is now being stretched into environments it was never built for.
Ingestion and Normalization Layer
The first layer of a traditional SIEM pipeline is ingestion. Logs are collected through syslog forwarding, endpoint agents, API connectors, or message queues. This layer is often assumed to be “solved,” but it’s actually one of the largest contributors to detection failure.
Cloud and SaaS telemetry does not behave like syslog. It is semi-structured, frequently inconsistent, and often changes schema without warning. Even within a single cloud provider, different services emit logs in different formats. When SIEMs ingest this data, they attempt normalizations, mapping raw fields into a standard schema such as user, source IP, destination, process, command, and so on.
But normalization is inherently lossy. You either preserve raw fidelity and sacrifice consistency, or you force everything into a generic schema and lose important context. For example, an AWS AssumeRole event includes identity relationships and trust context that do not map cleanly into a traditional “authentication event” schema. A Kubernetes audit log includes object metadata and API verbs that don’t align with Window-style event categories.
This is where many SIEM deployments quietly lose detection capability. The logs are present, but the semantic meaning is diluted. Once the SIEM loses semantic fidelity, correlation becomes weaker because correlation rules rely heavily on clean, consistent fields. In other words, the SIEM may have the data, but it cannot interpret it properly at scale.
Correlation Engines Based on IF-THEN Logic
At the core of the SIEM sits the correlation engine. This is where rule-based detection happens.
A correlation engine evaluates incoming events against a set of predefined rules. These rules typically follow deterministic logic patterns such as:
- If event type is “failed login” and count exceeds threshold within a time window → trigger brute force alert
- If user logs in from two distant geolocations within a short interval → trigger impossible travel alert
- If privileged group membership changes → trigger privilege escalation alert
This approach is fundamentally Boolean. The condition is either true or false. There is no concept of probability or confidence. If the rule matches, the SIEM generates an alert.
The engine may support more advanced constructs like chaining, nested conditions, or multi-stage correlations, but the detection philosophy remains the same: encoding suspicious behavior into deterministic conditions.
This is also why correlation rules become brittle. They assume the attacker’s behavior will match the detection engineer’s model of what an attack “should” look like. If the attacker slightly modifies their workflow, or if the environment behaves differently than expected, the rule breaks.
It’s not that correlation engines are poorly engineered. They do exactly what they were designed to do. The problem is that modern attacks rarely follow deterministic patterns that can be captured through static logic.
Time-Window Correlation Constraints
Almost all SIEM correlations are bounded by time windows. Rules operate over a defined interval such as 5 minutes, 30 minutes, or 24 hours. This is necessary because SIEMs process streaming data and cannot maintain an infinite historical state for every entity. But this introduces a major detection limitation: time windows assume attacks occur within predictable timeframes.
Modern adversaries do not operate that way. They routinely distribute actions over long periods to avoid threshold detection. Credential stuffing might occur over days. Lateral movement might happen once every few hours. Privilege escalation might be delayed until the attacker confirms access persistence.
If your SIEM correlation logic expects “N suspicious events in 10 minutes,” then any attacker who intentionally stretches their actions outside that window bypasses detection. This is not an edge case. This is standard adversary tradecraft.
Binary Output Model: Alert / No Alert
Finally, SIEMs typically output alerts as binary decisions. Either a rule fired or it didn’t. Either the event matches the condition, or it doesn’t.
This binary model is one of the biggest reasons SIEM systems generate overwhelming noise. The SIEM has no ability to say: “This looks mildly suspicious” versus “This is highly suspicious.” Instead, every rule match becomes an alert that competes for analyst attention.
SOC teams try to compensate by introducing severity levels, tuning thresholds, or suppressing repeated alerts. But these are operational hacks layered on top of a detection model that was never designed for probabilistic ranking.
This is why alert fatigue is an architectural outcome of deterministic detection systems. The SIEM produces too many alerts because it cannot express uncertainty. It only knows a match or no match.
Where Correlation Logic Breaks at Scale
Once log volume increases and telemetry sources expand, SIEM correlation rules begin failing in predictable ways. And what makes this failure dangerous is that it doesn’t always look like a failure. The SIEM still generates alerts. Dashboards still show activity. Reports still look “busy.” But the detection fidelity quietly collapses.
Instead of surfacing real threats, the SIEM becomes an expensive event router that produces excessive false positives while missing multi-stage attack patterns.
Rule Explosion and Operational Overload
The first breaking point is rule scaling. A SIEM rule is rarely independent. It depends on event parsing quality, field normalization, and assumptions about behavior. As the organization integrates more telemetry sources, cloud logs, SaaS audit logs, container telemetry, EDR alerts, IAM events, the number of potential correlation scenarios grows rapidly.
In theory, you could write correlation rules for everything. In practice, rule engineering becomes a combinatorial problem. Each new log source introduces:
- new event types
- new field structures
- new false positive patterns
- new dependencies between systems
And every time your team adds a rule, they also inherit the burden of tuning it. Because tuning isn’t optional. A raw correlation rule deployed at scale will almost always generate noise.
This is where SOC teams hit the operational wall: correlation rules don’t just increase linearly with telemetry. They increase super linearly, because cross-domain detection requires joining multiple data streams. You’re no longer writing rules for “Window logins” or “firewall blocks.” You’re writing rules for “Windows login + suspicious OAuth token issuance + anomalous API access + endpoint process behavior.” That’s not one rule. That’s an entire detection strategy.
Lack of Cross-Domain Context
The second breaking point is context. Modern attacks are identity-driven and multi-platform. An attacker might begin with a phishing compromise, then pivot into cloud control plane activity, then later access SaaS data repositories, and finally trigger endpoint execution through remote tooling.
If your SIEM correlation logic is operating on siloed log sets, it cannot see the attack as a single campaign. It sees fragments.
This is a structural limitation. Traditional SIEMs were built to correlate events within log categories, not to build a unified entity model across identity, device, session, and workload.
The correlation rule might detect suspicious login attempts. Another rule might detect unusual PowerShell execution. Another rule might detect an unusual AWS API call. But unless the SIEM has a strong entity resolution layer, mapping the same user identity across multiple systems, these alerts remain disconnected.
This is where detection fidelity collapses. The SOC sees isolated “medium severity” alerts instead of one high-confidence intrusion pattern.
And that is exactly what modern attackers exploit. They distribute their footprint across systems so that no single system sees enough evidence to trigger a high-severity detection.
Static Logic vs Evolving Adversaries
The third breaking point is adaptability. Correlation rules are essentially encoded threat assumptions. They reflect what the detection engineer believed an attacker would do at the time the rule was written.
But adversaries do not behave like static models. Their TTPs evolve continuously. Malware changes behavior. Attackers randomize command sequences. They use living-off-the-land tools. They shift to credential abuse instead of malware deployment. They move to token theft and OAuth abuse instead of password guessing.
A SIEM correlation engine cannot adapt unless humans continuously rewrite rules. And that is an impossible scaling requirement. SOC teams are already overwhelmed with triage, response, reporting, compliance, and platform management. Expecting them to continuously rebuild detection logic at the same pace as adversaries is unrealistic.
This is why correlation logic fails at scale: it requires constant human engineering to remain relevant. And once telemetry complexity increases, the rule-writing workload becomes unsustainable.
At that point, the SIEM becomes a legacy system that still produces alerts but no longer produces reliable detection.
Failure Under Modern Attack Path Semantics
One of the biggest misconceptions about SIEM correlation is that it fails because organizations don’t write “enough rules.” In reality, most mature enterprises already have hundreds or thousands of rules. The problem is that modern intrusions are not single events. They are attack paths, distributed sequences of activity across identity systems, endpoints, cloud platforms, SaaS applications, and network infrastructure.
And SIEM correlation engines were never designed to model attacks paths. They were designed to match patterns.
That difference matters, because an attack path is not a simple set of conditions. It is a probabilistic storyline: a series of actions that may be spaced out over time, executed through multiple identities, and partially hidden behind normal system noise.
Rule-based SIEMs struggle because they don’t reason about “what is happening overall.” They only evaluate whether individual fragments match known detection logic.
Multi-Stage Attack Decomposition Gap
Modern adversaries rarely “hack” and organization in a single step. Instead, intrusions unfold as staged operations. Even commodity ransomware groups now behave like structured threat actors.
A typical attack chain looks like this:
- initial access (phishing, credential theft, exposed service exploitation)
- privilege escalation (token theft, misconfig exploitation, local admin escalation)
- lateral movement (RDP, WinRM, SMB, cloud-to-cloud pivoting, service account abuse)
- persistence and staging
- data exfiltration
- ransomware deployment or impact execution
The problem is that SIEM correlation does not natively model this chain as one continuous operation. Instead, each stage becomes its own alert cluster.
Your SIEM might fire a detection for “suspicious login.” Then separately fire an alert for “new admin group membership.” Later, it might generate a lateral movement alert. Then a data transfer anomaly alert.
From a detection engineering standpoint, these alerts should not be independent. They should amplify each other. A suspicious login alone may be a false positive. But a suspicious login followed by privilege escalation and then lateral movement is almost never benign.
SIEM correlation rules rarely build this full narrative because doing so requires long-range dependency tracking across multiple domains. Most correlation engines cannot maintain stateful context over long time periods without becoming computationally expensive and operationally fragile. So, they fall back to short-window correlations, and the attack chain becomes fragmented.
This is exactly how real breaches slip through: the SOC sees scattered low-severity alerts instead of a single high-confidence intrusion.
Identity-Centric Attack Bypass
If you still think in terms of endpoints and IP addresses, modern attack paths will look invisible. Today’s intrusions are identity-first.
Attackers don’t always need malware execution if they can compromise identity systems. Once they steal credentials, access tokens, or session cookies, they can operate entirely inside legitimate authentication flows. This is why credential-based lateral movement has become one of the most dominant intrusion patterns in cloud and hybrid environments.
The issue is that identity telemetry is noisy and high-dimensional. A single user might authenticate across multiple SaaS platforms, cloud services, and devices daily. If an attacker reuses a session token or pivots across cloud services, the events look legitimate at the log level.
This is where SIEM correlation struggles. It may correlate within one identity provider (like Azure AD sign-in logs), but it often fails to correlate session behavior across distributed systems. The SIEM sees a valid login event. It sees valid API calls. It sees valid SaaS access. It may not have enough context to identify that these “valid” actions are part of an abnormal access pattern.
This is why token theft is so effective. The attacker isn’t breaking authentication rules; they are abusing legitimate sessions.
And correlation rules generally fail here because they assume malicious behavior looks structurally different from normal behavior. Identity-centric attacks violate that assumption. The attacker is using the same protocols, the same APIs, and the same identity objects as legitimate users.
Without behavioral baselines and entity-level risk scoring, rule-based correlation becomes blind.
Low-and-Slow Evasion
Threshold rules are one of the most common SIEM detection patterns: “N events in X minutes.” That’s also why low-and-slow attacks remain effective.
Attackers understand SOC tuning behavior. They know organizations suppress noisy detections. They know SIEM rules often have strict time windows because long time windows generate too many false positives. So, adversaries simply stretch their operations over time.
Instead of 50 authentication attempts in 2 minutes, they do 5 attempts every hour. Instead of scanning the environment aggressively, they probe gradually. Instead of moving laterally in a single burst, they pivot once a day. This is particularly common in insider-like intrusion patterns, where attackers want to remain stealthy and avoid alerting.
SIEM correlation engines are not designed to detect long-range temporal dependencies. They don’t model the fact that “this user has been behaving slightly unusually for 14 days” or “this service account has gradually increased privilege scope across multiple cloud resources.”
They are engineered for immediate pattern recognition, not longitudinal behavioral analysis.
This is a critical architectural gap. Many real-world intrusions are not noisy enough to trip static thresholds, but they are statistically abnormal when viewed over longer horizons.
Rule-based SIEM correlation typically cannot maintain that horizon without becoming operationally unusable.
Polymorphic Behavior Blindness
One of the most damaging assumptions in rule-based correlation is that attacker behavior is stable. That assumption is outdated.
Modern malware families are polymorphic. They mutate binaries, randomize execution paths, and alter command sequences to evade deterministic detection logic. Even when the attacker is using “legitimate” tools like PowerShell, WMI, PsExec, or cloud CLI utilities, they can vary execution in subtle ways that break static rules.
A correlation rule might detect a known malicious process chain. But attackers can introduce benign intermediate processes. They can rename binaries. They can execute from alternate locations. They can use memory injections instead of disk execution. They can shift to LOLBins and blend into normal administrative activity.
This is where deterministic rule logic becomes brittle. A rule only matches what it was explicitly designed to match. If the attacker changes even one condition, command-line flags, parent-child process relationships, timing, execution context, the correlation fails.
This is why signature-driven correlation and deterministic detection conditions degrade over time. The attacker’s behavior has high variance, but the SIEM rule assumes low variance.
At scale, this becomes catastrophic: the SIEM produces thousands of alerts for known noisy patterns, while sophisticated adversaries quietly bypass detection by introducing randomness.
Alert Fatigue as a Deterministic System Output
SOC leaders often treat alert fatigue as a staffing problem. The narrative usually goes: “We need more analysts,” or “We need better processes,” or “We need to tune our SIEM.”
But alert fatigue is not just operational friction. In most rule-based SIEM environments, it is the mathematically predictable outcome of deterministic detection.
A SIEM rule engine produces alerts when conditions match. It has no built-in understanding of uncertainty. It cannot reason probabilistically. It cannot say: “this looks 20% suspicious” versus “this is 95% suspicious.” It can only say: matched or not matched. And that is why noise becomes inevitable.
The moment you tune rules to avoid missing threats, false positive explodes. The moment you tune rules to reduce noise, detection coverage collapses. This is not a tuning mistake; it is the inherent tradeoff of rigid rule thresholds.
Over time, the SOC ends up operating in a broken equilibrium:
- rules are tuned conservatively to reduce noise
- attackers operate below thresholds
- detections become weak
- analysts stop trusting SIEM alerts
- high-confidence incidents are buried inside low-confidence alert volume
Anton Chuvakin’s observations about SIEM content engineering and false positives map directly to this reality. SIEM content is often marketed as “detection intelligence,” but in practice it generates huge amounts of low-signal alerts because it cannot incorporate environmental context.
The rule engine doesn’t understand whether a system is critical, whether a user is privileged, whether an IP is expected, or whether a behavior is statistically rare for that organization. It just sees an event pattern.
This is why SOC analysts become the de facto correlation layer. Humans start doing what the correlation engine cannot: reasoning context, chaining events mentally, and deciding whether the alert represents an actual intrusion. On a small scale, this might be manageable. On an enterprise scale, it becomes impossible.
Once log volumes increase and alert volume grows, the signal-to-noise ratio collapses. Analysts start triaging alerts based on instinct, experience, and time constraints rather than structured evidence. This is where SOC burnout happens, and this is also where real incidents get missed.
Alert fatigue isn’t just about too many alerts. It’s about the SIEM producing alerts that lack enough context to justify analysts’ attention. And in deterministic correlation systems, that outcome is expected.
Data Fragmentation and Loss of Detection Fidelity
Even the best correlation rules fail if the underlying telemetry is fragmented. And in modern environments, fragmentation is the default state.
Organizations don’t have one logging pipeline. They have dozens. They collect endpoint logs through EDR platforms, identity logs from IAM providers, SaaS audit logs from cloud apps, network telemetry from firewalls, DNS resolvers, proxies, and cloud-native networking layers. Each source has its own schema, its own event semantics, and its own limitations.
SIEMs ingest all of this, but ingestion is not the same as unification. The real detection problem is not log collection. It is a semantic alignment. Without alignment, correlation becomes shallow.
Telemetry Silos
The modern SOC runs across multiple telemetry categories:
- endpoint process execution and memory telemetry
- cloud control plane audit events
- identity provider authentication logs
- SaaS activity logs (SharePoint, Google Workspace, Salesforce, etc.)
- network flow records and proxy logs
Each of these sources represents a different view of reality. Endpoint telemetry tells you what executed. Cloud audit logs tell you what API calls were made. Identity logs tell you what authenticated. Network logs tell you where traffic moved.
But SIEM correlation engines often treat these sources as separate streams because they lack a unified event ontology. The result is that even if all logs exist, the SIEM cannot easily express cross-domain detections without extensive custom engineering.
This is why detection coverage collapses in cloud-heavy environments. The intrusion is distributed, but the telemetry is not unified.
Missing Entity Resolution Layer
Correlation depends on one thing more than anything else: identity mapping. In a modern environment, the same “actor” might appear in telemetry as:
- a human user account
- an OAuth application
- a service principal
- a Kubernetes service account
- an endpoint hostname
- a device ID
- an IP address that changes frequently
- a cloud workload identity
If your SIEM cannot reliably map these into a single entity model, correlation becomes meaningless.
For example, consider a cloud intrusion where an attacker steals a token, uses it to access a storage account, and then triggers an endpoint execution through a management API. The SIEM might log these events, but without entity resolution it cannot reliably link them as the same attacker activity.
You need a consistent mapping between:
user ↔ device ↔ session ↔ IP ↔ workload
Traditional SIEM correlation was not built for this. It was built for stable hostnames, static IPs, and predictable user accounts. In cloud-native environments, those anchors disappear. Without entity resolution, you don’t have correlation. You have log aggregation.
Lack of Enrichment Pipelines
Even when logs are normalized, correlation still fails without enrichment.
A raw authentication event is not meaningful unless you know whether the account is privileged, whether the device is managed, whether the IP is expected, and whether the resource being accessed is sensitive.
Enrichment pipelines provide that missing context by injecting metadata such as:
- asset criticality (production workload vs test system)
- identity risk scoring (privileged admin vs normal user)
- behavioral baselines (typical login time, location, device usage patterns)
Most SIEM deployments either lack enrichment entirely or apply it inconsistently. This creates a huge detection problem: correlation rules must be written in a generic way, because the SIEM doesn’t know which events matter more.
That generic rule logic is exactly what creates false positives. The SIEM cannot distinguish between a suspicious event on a domain controller versus the same event on a developer laptop. So, both generate alerts.
This is how detection fidelity degrades. The SOC sees too many alerts that are technically “correct” but operationally irrelevant. And once analysts start ignoring irrelevant alerts, real threats hide in plain sight.
Why Rule-Based Systems Cannot Adapt to Evolving TTPs
At the heart of the SIEM problem is one brutal fact: rule-based detection does not evolve automatically. A correlation rule is manually encoded logic. It represents a snapshot of threat knowledge at a specific moment. But attackers don’t operate in snapshots. They evolve continuously.
The SIEM update lifecycle is slow because it depends on multiple human-driven steps:
Threat intelligence has to be ingested. Detection engineers must translate it into correlation logic. The rules must be tested. It must be deployed. Then it must be tuned in production because every environment behaves differently. And tuning often requires weeks of feedback cycles. Meanwhile, adversaries iterate in days.
They change payload delivery methods. They switch to new command execution techniques. They abuse new cloud services. They adopt new living-off-the-land binaries. They exploit misconfigurations unique to modern infrastructure. This creates a permanent detection gap. The SIEM rule-base is always behind the threat landscape.
Even worse, as organizations move deeper into cloud, the attack surface itself evolves faster than rule engineering teams can track. New SaaS applications are onboarded. New APIs appear. New authentication methods are deployed. Each change introduces new telemetry patterns, and those patterns can invalidate existing rules.
This is why rule-based SIEM systems don’t just struggle with attacker evolution, they struggle with infrastructure evolution.
A SOC ends up fighting two moving targets:
- attackers changing TTPs
- environments changing telemetry semantics
Rule-based detection is not built for that reality. It assumes stability. It assumes that detection engineers can encode threats into logic and maintain that logic indefinitely. At enterprise scale, that assumption fails.
And once it fails, the SIEM becomes what many SOCs quietly admit it has become: a compliance platform and log repository, rather than a true detection engine.
AI-Assisted Detection Architecture
Once you accept that correlation logic fails because it’s deterministic, the next question becomes obvious: what replaces it?
The answer is not “more rules.” It’s not even better automation around rule writing. The real shift is architectural: moving from deterministic detection (rules) to probabilistic detection (models). That change is fundamental, because it alters how a SOC interprets telemetry.
Instead of asking “does this event match a predefined suspicious condition?” the system starts asking “how likely is this behavior to represent malicious activity, given everything else happening across the environment?”
That shift is exactly why AI-assisted detection is not simply SIEM with automation bolted on. It is a different detection paradigm entirely.
Transition from Deterministic to Probabilistic Detection
Traditional SIEM rules operate like gates. If a condition is satisfied, an alert is generated. If it isn’t, the event is discarded or stored silently. That’s a binary decisioning model. AI-assisted detection replaces this with continuous scoring.
Instead of labeling an event as “malicious” or “benign,” the system assigns a risk score based on probability and confidence. That risk score is derived from multiple signals, not a single condition. For example, a login from an unusual geography may not be enough to trigger an incident. But if that login is followed by suspicious token issuance, privilege escalation activity, and abnormal access to cloud resources, the probability of compromise becomes high.
This is where probabilistic inference becomes more realistic than deterministic correlation. Real-world attacks rarely produce one definitive signal. They produce a cluster of weak indicators that only become meaningful when combined.
This also solves one of the biggest weaknesses of SIEM: the inability to express uncertainty. In a probabilistic model, uncertainty is not a failure state; it is part of the output. You can represent risk as a gradient rather than a switch.
This is why AI-assisted detection reduces false positives. Instead of firing alerts on every suspicious event, it can rank events by likelihood of maliciousness, prioritizing analyst attention where it matters.
Cross-Domain Feature Aggregation
A major reason AI detection works better is that it treats security telemetry as a feature space rather than as isolated log messages. In rule-based SIEM correlation, you correlate “events.” In AI-assisted detection, you correlate signals, and signals are derived from telemetry across multiple domains.
This requires building a unified representation of activity from sources such as:
- identity signals (IAM authentication logs, SSO events, conditional access results)
- endpoint telemetry (process execution trees, parent-child relationships, command lines, memory indicators)
- cloud control plane events (AWS CloudTrail, Azure Activity Logs, GCP audit logs)
- network metadata (NetFlow, DNS queries, proxy activity, TLS fingerprinting)
Once these are normalized, the detection engine can build feature vectors. In practical terms, this means a user session is no longer represented as a single “login event.” It becomes a structured object containing attributes like device posture, authentication method, location history, token usage patterns, and access graph behavior.
This is exactly what correlation rules struggle to do, because rules are not good at feature fusion. They are designed for conditional matching, not statistical representation.
Feature aggregation also enables entity-based detection, where the system evaluates risk for an entity (user, device, workload, service account) rather than for an individual log entry. That distinction matters because attackers compromise entities, not logs.
Temporal Sequence Modeling
Correlation rules typically operate in short-term windows. That’s a limitation of both computation and logic design. But modern attacks are not always short-window patterns. AI detection systems can model sequences.
Instead of evaluating one event at a time, they evaluate event chains. That means detection is based on behavioral progression, not isolated triggers. For example, a rule-based SIEM might fire on “failed logins > 10.” But an AI model can detect that a user session is evolving abnormally even when no single threshold is exceeded.
This is especially critical for detecting:
- lateral movement spread across hours or days
- credential misuse where logins look valid
- persistence operations executed gradually
- privilege escalation chains that involve multiple subtle actions
Temporal sequence modeling essentially treats attacks as state transitions. The system tracks that an entity moved from normal state → suspicious state → high-risk state.
This is exactly what a SOC analyst does mentally when investigating an incident. AI-assisted detection simply operationalizes it at a machine scale.
And unlike rule engines, sequence modeling is not limited to predefined “attack playbooks.” It can detect novel behavioral chains as long as they deviate statistically from baseline patterns.
Noise Suppression via Learned Baselines
This is where AI-assisted detection becomes especially powerful: it suppresses noise without relying on static suppression rules. In a SIEM, noise reduction is typically done through tuning:
- increasing thresholds
- suppressing alerts from specific users or hosts
- adding exclusion logic
- creating whitelists
But whitelisting is dangerous. It creates blind spots. And threshold tuning often removes detection coverage.
AI systems approach noise differently by learning baselines. Instead of assuming that all logins at midnight are suspicious, the model learns that a specific DevOps engineer frequently logs in at midnight. Instead of assuming that all PowerShell execution is malicious, the model learns which endpoints regularly run automation scripts and which do not.
Baseline behavior modeling can be applied per entity, such as:
- per user
- per device
- per service account
- per cloud workload
Then anomaly detection becomes contextual. The system doesn’t ask “is this behavior suspicious globally?” It asks, “is this behavior suspicious relative to what is normal for this entity?”
That dramatically improves detection fidelity. It reduces false positives while preserving detection sensitivity. And importantly, it reduces the need for endless rule tuning cycles, which is where SIEM operations typically burn out.
AI SOC vs Rule-Based SIEM: Architectural Comparison
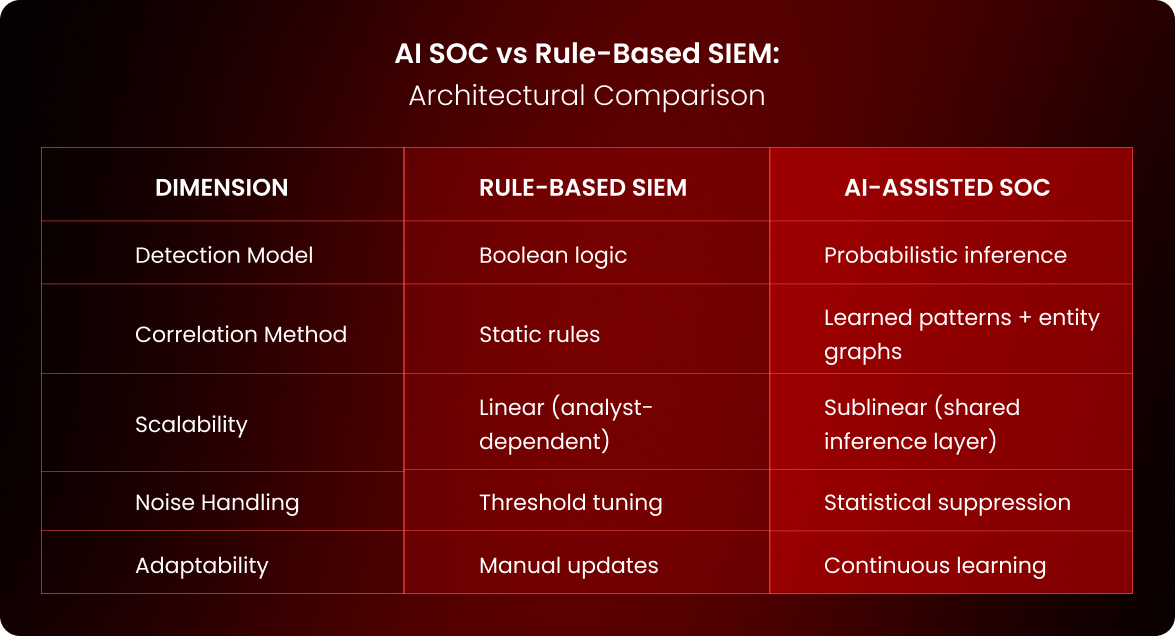
Multi-Tenant SOC / SECaaS Implications
In a multi-tenant SOC model, the biggest challenge isn’t log ingestion; it’s cost and operational scalability. Rule-based SIEM deployments demand constant per-client tuning, rule maintenance, enrichment updates, and analyst-heavy triage. As telemetry grows, the workload scales linearly, and the economy quickly breaks.
That’s why SIEM-driven MSSP delivery often becomes inefficient at scale. When licensing, storage, compute, and tuning overhead are combined, the per-client burden can easily reach significant costs, especially if the goal is meaningful detection rather than compliance logging.
Ebryx’s SECaaS model addresses this directly by using shared detection pipelines rather than building isolated correlation logic per tenant. Instead of scaling analysts and rule engineering for every client, Ebryx leverages AI-assisted detection to absorb noise, prioritize high-risk activity, and deliver consistent detection coverage across environments. The outcome is simple: better detection without unsustainable per-tenant operational cost.
Zero Trust Alignment Through Identity-Centric Correlation
Zero Trust has shifted the detection focus from network boundaries to identity behavior. Most modern breaches are credential-driven, involving token theft, OAuth abuse, and session hijacking, activities that often appear legitimate in raw logs.
Ebryx aligns with this reality by emphasizing identity-centric detection, correlating signals across IAM, endpoints, cloud control planes, and SaaS activity. Instead of relying on static thresholds, Ebryx SOC pipelines evaluate trust continuously by tracking abnormal authentication patterns, privilege expansion, session anomalies, and risky access paths.
This identity-first correlation approach fits naturally into Zero Trust environments, where the real perimeter is the user, device posture, and session integrity, not the firewall.
Conclusion
Rule-based SIEM is not “bad,” but it is structurally constrained. Stateless correlation, binary alerting, and fragmented telemetry lead to alert overload and weak attack-chain detection.
Ebryx moves beyond correlation-only detection by delivering SECaaS through AI-assisted SOC pipelines that fuse cross-domain telemetry, model behavioral sequences, suppress noise, and prioritize risk probabilistically. This allows Ebryx to provide scalable, high-fidelity detection that works in cloud-native, identity-driven environments, without the heavy per-client SIEM tuning and cost overhead.
SUMMARIZE WITH AI



